
Cam Foreground
I must admit that I’m sort of fascinated by the whole camgirl phenomena. Not in some entirely salacious way mind you; I find it fascinating, but fascinating in the way that say Superhero movies are fascinating, which is: isn’t it fascinating that such a thing exists and even more fascinating to ponder how it came to exist?
And in both cases too, I feel like I really must be missing something. Because—and although it’s generally considered to be rather crass to disparage other people’s fancies—I have to question: is this really the best we can do? For even from the most basic viewpoint, it seems that most cams are like whatever the opposite of erotic is. A-rotic maybe? On multiple levels really. And when I’ve railed against unimaginative, push-button intimacy, the current camgirl (or camboy for that matter) formula is pretty much what I’m talking about.
But at the same time you really just can’t look away! And so recently, in hopes of furthering my pop cultural sensibility and general cyber savvy, I undertook a short visual study of camgirl footage. However as watching all those pixels in realtime would have taken far too long, I opted to approach the problem algorithmically. My theory was that by applying various foreground detection techniques to the streams, I presumably could cut them down to just the important bits, and that these bits would hold the key to understanding camgirl sites and the larger society that created them. Sounded perfectly reasonable.
Process
Foreground detection takes a video and segments each frame into a foreground and background. For a stationary camera, the simplest way to do this is to take a static image as the background and diff every frame against it; if a pixel’s difference against the background is greater than a given threshold, mark that pixel as part of the foreground. The output of a foreground detection algorithm like the one just described is generally an image mask that identifies the foreground elements in the input frame.
In most real world cases however, backgrounds can evolve: objects may change positions, lighting conditions may change, or the camera itself may shift. More advanced foreground detection algorithms handle this by maintaining an evolving model of the background. When a new frame comes in, the algorithm generates the foreground mask from its model and also updates its model of the background. A simple example of this approach would be comparing each frame against the previous frame.
Here is the output of a basic foreground detection script:
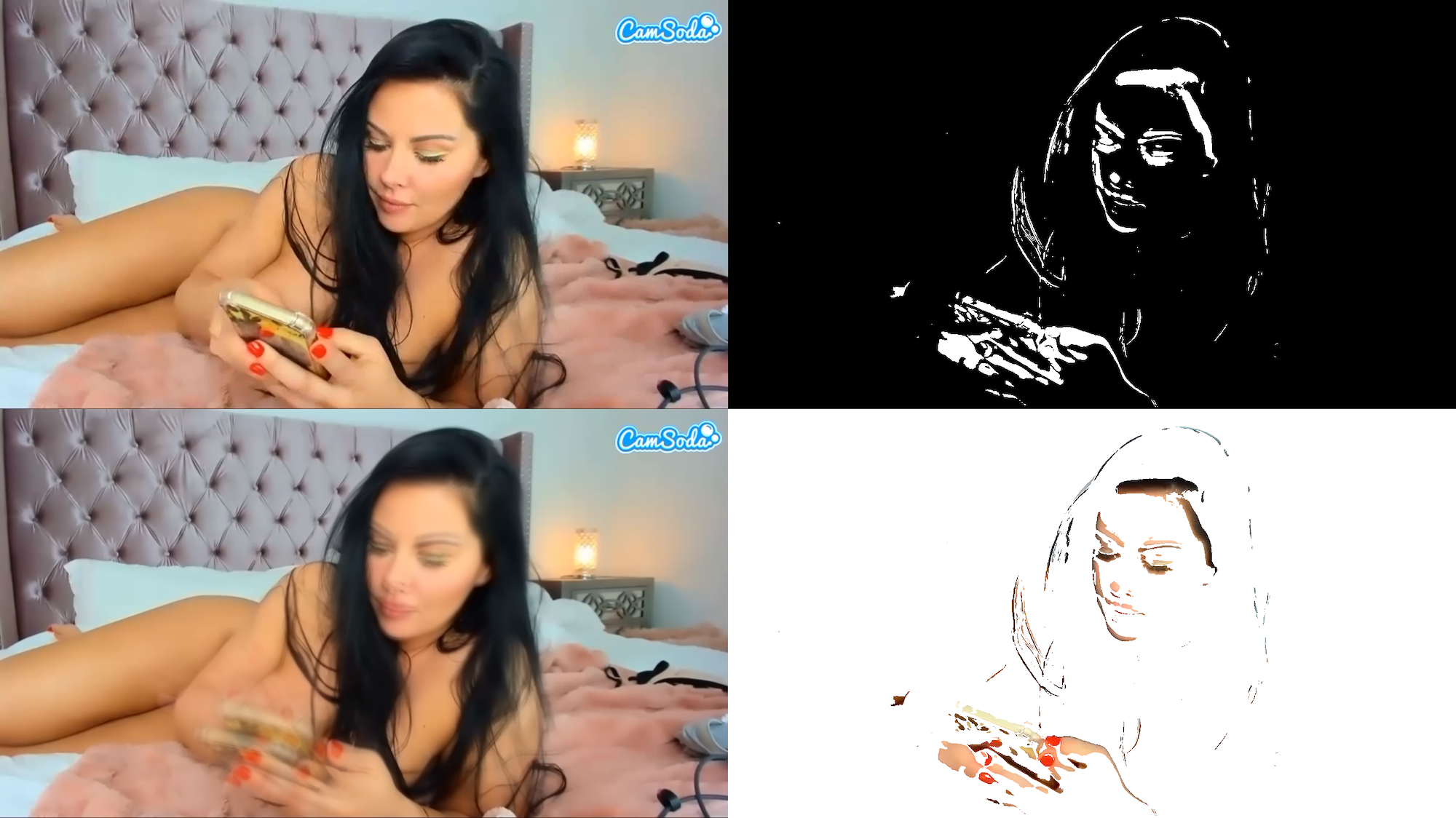
From top-left clockwise: input, the foreground mask, the result of applying the mask, and the background model
Cam footage is almost made for foreground detection, as it mainly consists of long shots using a stationary camera. Perhaps what’s most surprising is that there isn’t already a subreddit dedicated to this pairing.
Masks
I began my study by applying a number of different foreground detection algorithms to the sample clips from CamSoda. For data collection, I basically just went to the site one Saturday evening and sampled from streams that had the most viewers at the time.
Although some algorithms worked better objectively than others, I found that even many of the inferior results were quite intriguing both as stills and as videos. In the masks below, white is foreground while black is background.


}











However, I was at first rather taken aback that my simplistic approach to foreground detection was often producing results that look closer to edge detection. After some investigation, I believe this is because the algorithms have difficulty tracking motion if the object in motion is of a fairly uniform color. This mainly showed up for skin in these videos. Movement of objects with hard edges—such as eyes or hair or lingerie—are generally easily distinguished, while a moving patch of skin would be treated as unchanged.
Overall though, I can’t help but find the glitchy aesthetic of these black-and-white masks to be more appealing than the source material. Could it be that the imperfection of the simulacrum is not a defect as I had long assumed, but actually part of the appeal? If so, then the true connoisseur must surely be booting up a TRS-80 for their Saturday night browsing.
Foregrounds
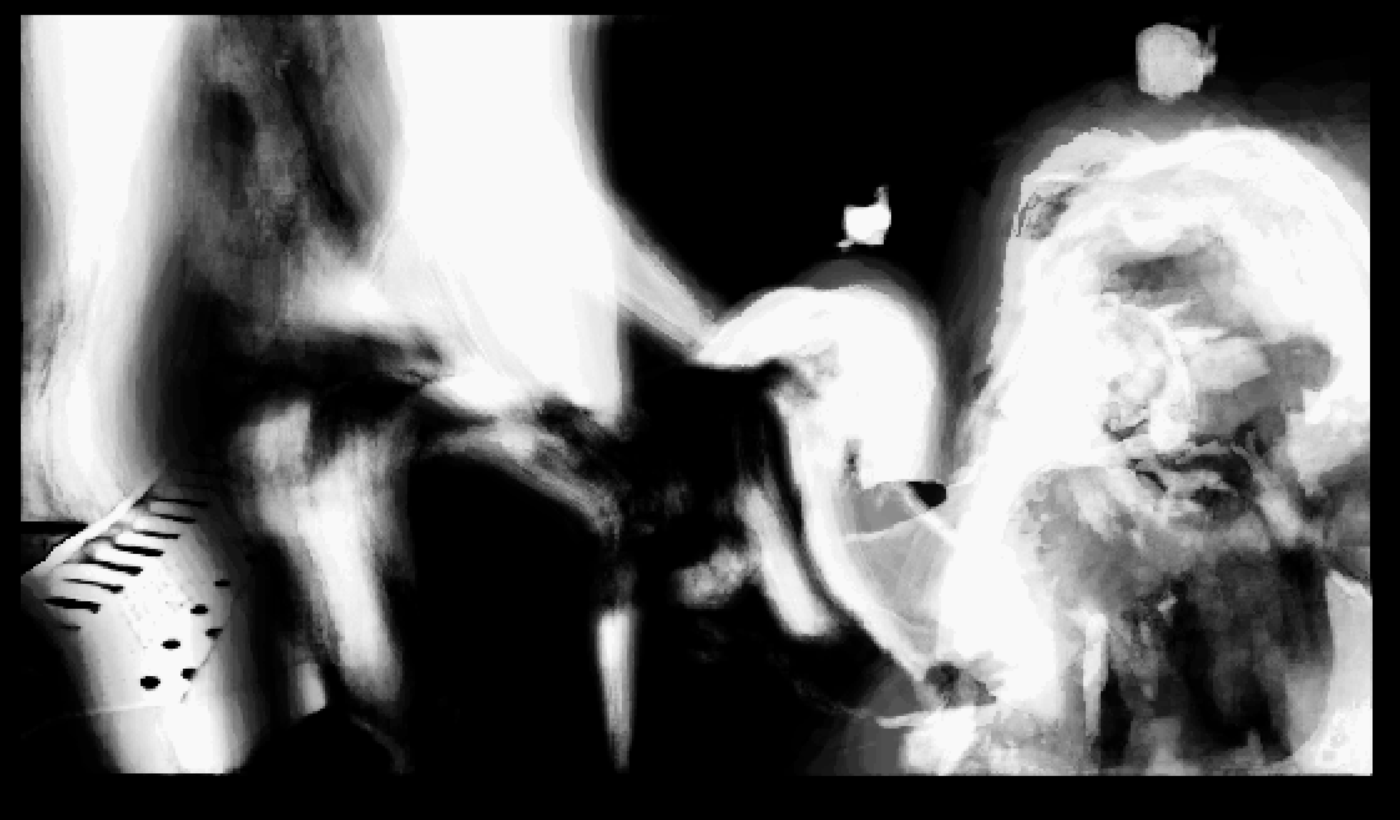
To put this theory to the test, I next tried adding back some fidelity. This was done by re-applying the masks back to the original videos, creating stills or videos of just the foreground elements.




Despite going from a 1 bit mask to a glorious 24 bit rainbow, somehow it’s almost even more abstract to watch the ghostly outline of a hand or leg go floating around this white void. And personally, I just could not shake the feeling that things are often more intriguing when more is left to the imagination. Clearly my understanding was still quite lacking.
Backgrounds
While trying to tweak the foreground detection process to produce better results, I happened to glimpse the background model images that the algorithms were generating. These too were quite interesting artifacts, and worthy of examination.








Although the model images can touch on cubism and impressionism, what they capture is what might be called a mechanical view. While such a detached, arotic presentation of the subject may not help understanding popular tastes, I do think these algorithmic outlooks are quite revealing in their own right.
Volumes
However, by this point, the project was really turning into quite a slog. Maybe it was the saturation. And although I was not aiming for a comprehensive review of the field, even from my limited study, the videos were starting to feel a bit formulaic. So I began looking for ways to condense things.
My solution was to extrude either the masks or isolated foregrounds out into three dimensional volumes, creating a single 3D object that captures the essence of each video. This is an approach I’ve used before, and it was also an opportunity to examine the importance of time in these videos.

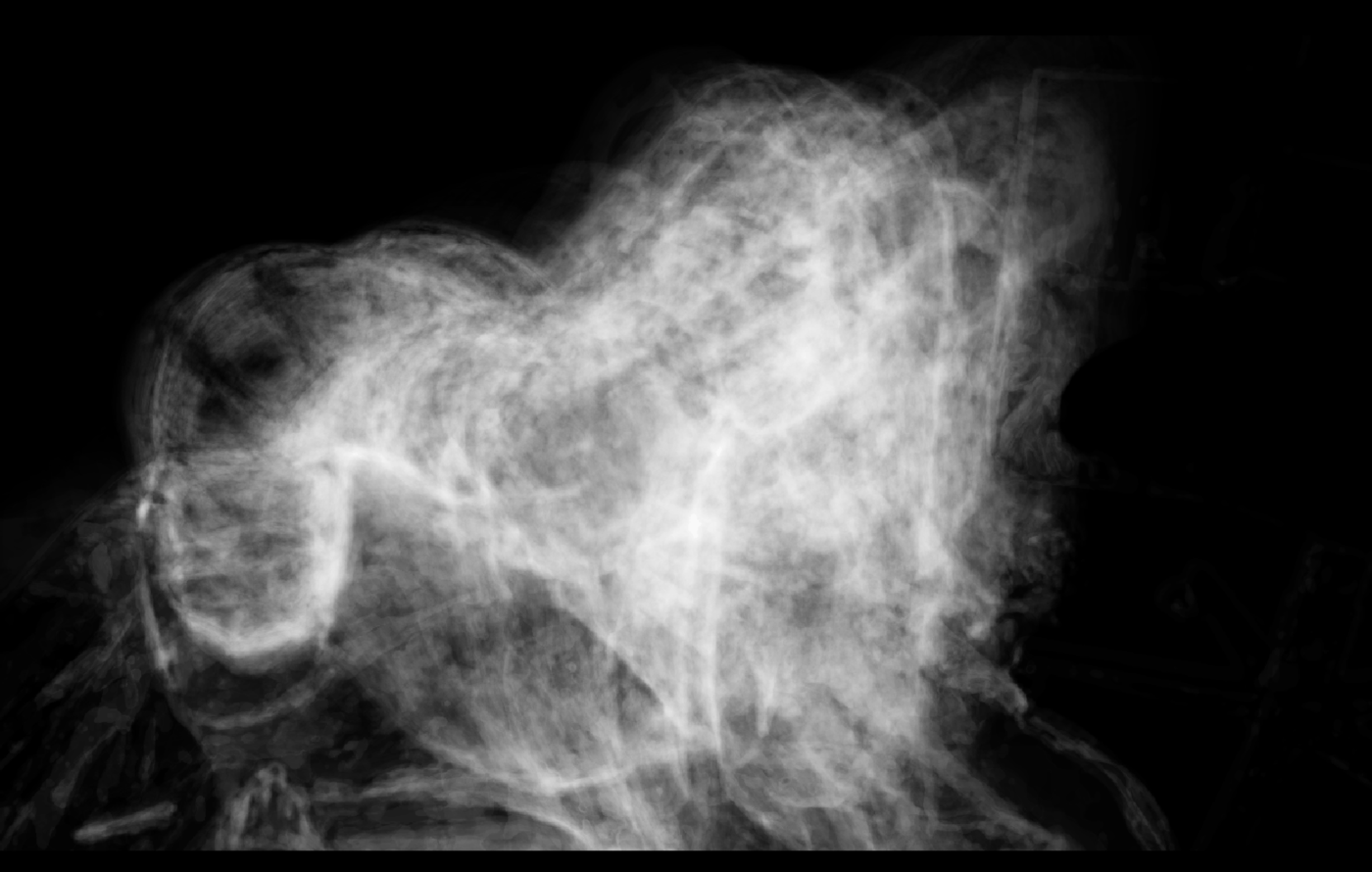






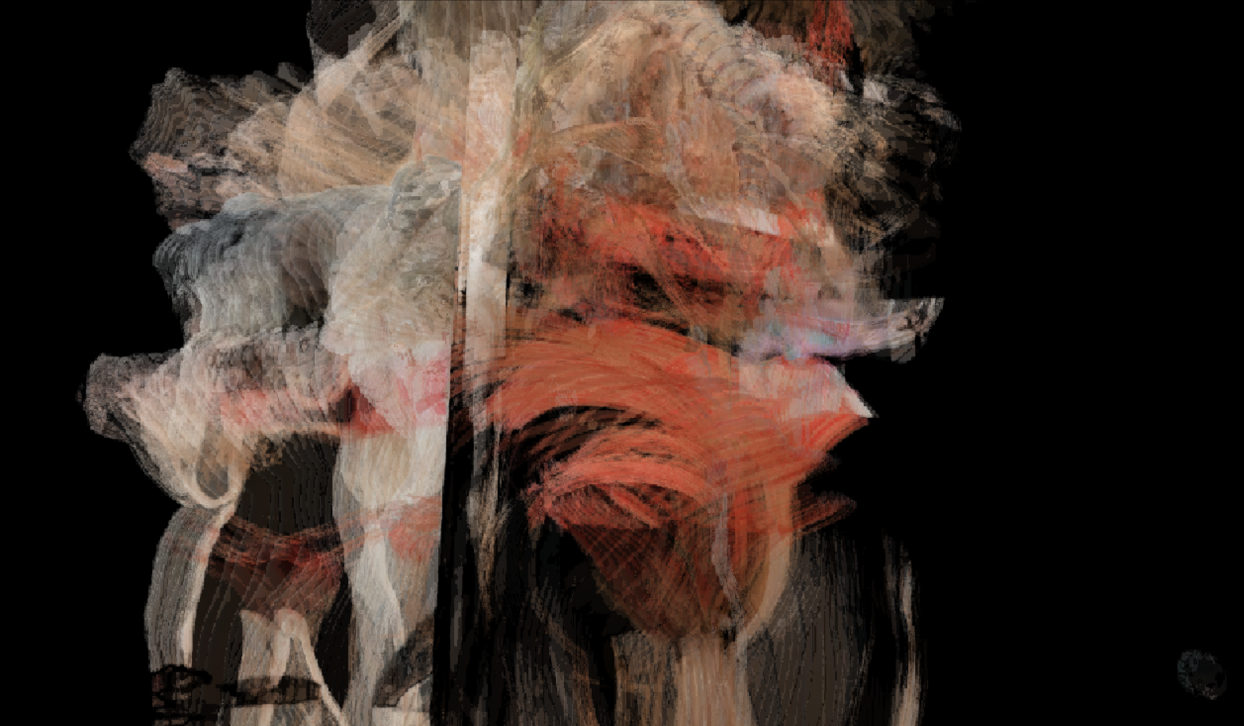


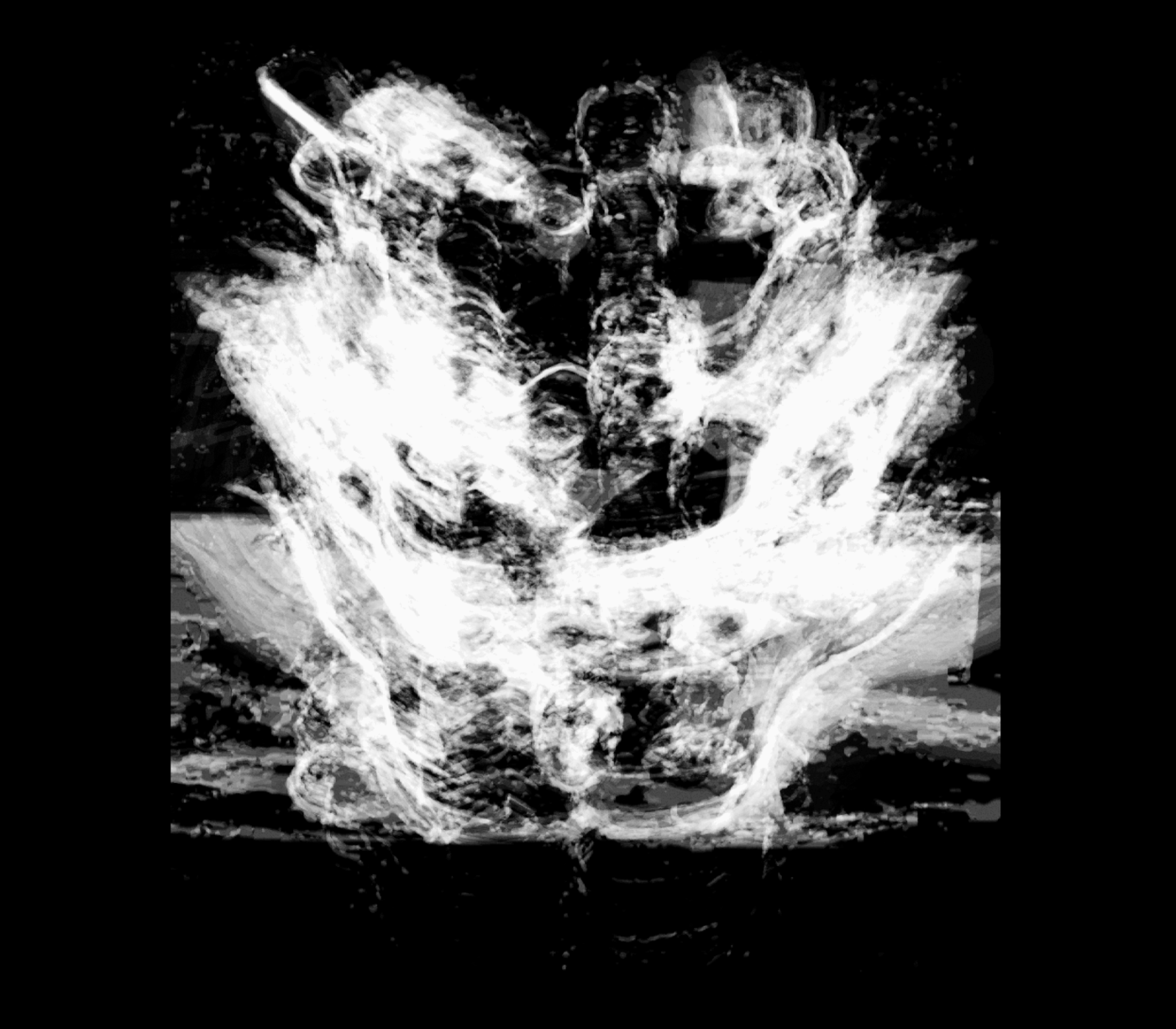


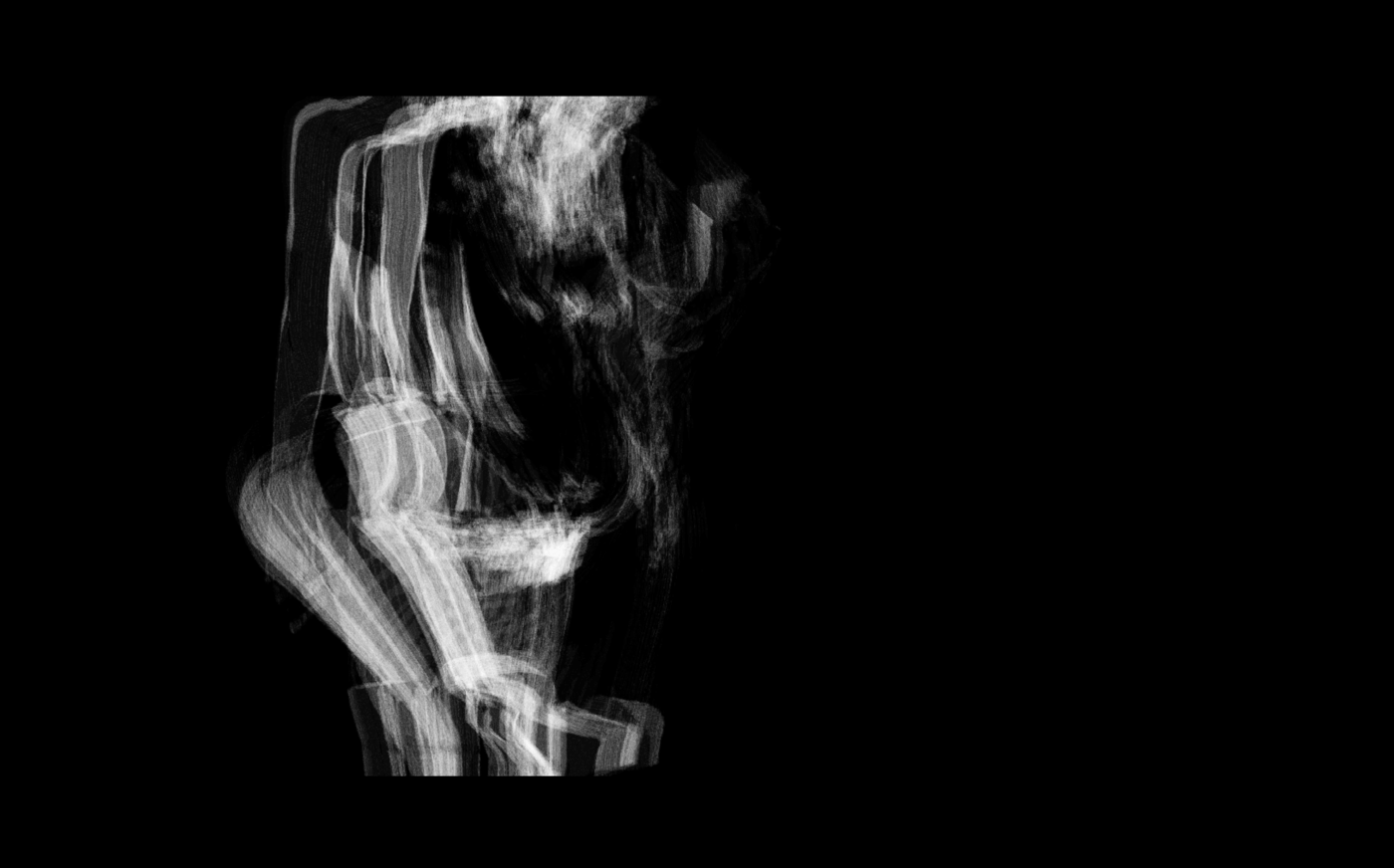

While some of these volumes are quite visually striking, unfortunately such “objectification”—as I’ve coined the above process—did not seem relevant to the project at hand, although I don’t doubt that it may someday find application in mass media. Therefore, I did not continue my exploration into higher dimensionalities, and instead decided to call it.
Conclusion
So what did we learn? What can we conclude about these sites where women in video boxes dance, or play with rubber penises, or—maybe for a few tokens—play girlfriend for a little while? While I can’t say that my personal opinion has changed, from this initial study I do feel that we can safely conclude that something about backgrounds and foregrounds seems relevant, although the exact nature of the relationship remains to be determined.
Stream Credits:
- CandyAndFox
- FOXXX
- Katt Leya
- Malibu Bomb
- Mileena Kane
- Wettdiamond
- Yummy Cakes
Thank you. I hope it’s clear this project was never meant to be critical of you or what you do.